La famille de modèles Deepseek-R1 récemment publiée a apporté une nouvelle vague d’excitation à la communauté de l’IA, permettant aux passionnés et aux développeurs de gérer des modèles de raisonnement de pointe avec des capacités de résolution de problèmes, de mathématiques et de code, le tout de la confidentialité de la confidentialité de PCS locaux.
Avec jusqu’à 3 352 billions d’opérations par seconde de puissance AI, les GPU de la série NVIDIA GEFORCE RTX 50 peuvent exécuter la famille Deepseek de modèles distillés plus rapidement que tout sur le marché des PC.
Une nouvelle classe de modèles qui raisonnent
Les modèles de raisonnement sont une nouvelle classe de modèles de grand langage (LLM) qui passent plus de temps à «penser» et à «réfléchir» pour résoudre des problèmes complexes, tout en décrivant les étapes nécessaires pour résoudre une tâche.
Le principe fondamental est que tout problème peut être résolu avec une réflexion, un raisonnement et un temps profonds, tout comme la façon dont les humains s’attaquent aux problèmes. En passant plus de temps – et donc à calculer – sur un problème, le LLM peut donner de meilleurs résultats. Ce phénomène est connu sous le nom de mise à l’échelle du temps de test, où un modèle alloue dynamiquement les ressources de calcul pendant l’inférence à la raison par des problèmes.
Les modèles de raisonnement peuvent améliorer les expériences des utilisateurs sur les PC en comprenant profondément les besoins d’un utilisateur, en prenant des mesures en leur nom et en leur permettant de fournir des commentaires sur le processus de réflexion du modèle – déverrouiller les workflows pour la résolution de tâches complexes et en plusieurs étapes telles que l’analyse des études de marché, la performance Problèmes mathématiques complexes, code de débogage et plus encore.
La différence profonde
La famille Deepseek-R1 de modèles distillés est basée sur un grand modèle de mélange d’Experts (MOE) de 671 milliards de dollars. Les modèles MOE se composent de plusieurs modèles d’experts plus petits pour résoudre des problèmes complexes. Les modèles Deepseek divisent en outre le travail et attribuent des sous-tâches à des ensembles plus petits d’experts.
Deepseek a utilisé une technique appelée distillation pour construire une famille de six modèles étudiants plus petits – allant de 1,5 à 70 milliards de paramètres – du grand modèle de paramètre de 671 milliards de dollars. Les capacités de raisonnement du plus grand modèle Deepseek-R1 de 671 milliards de dollars ont été enseignées aux modèles d’étudiants LLAMA et QWEN plus petits, ce qui entraîne des modèles de raisonnement puissants et plus petits qui fonctionnent localement sur des PC RTX avec des performances rapides.
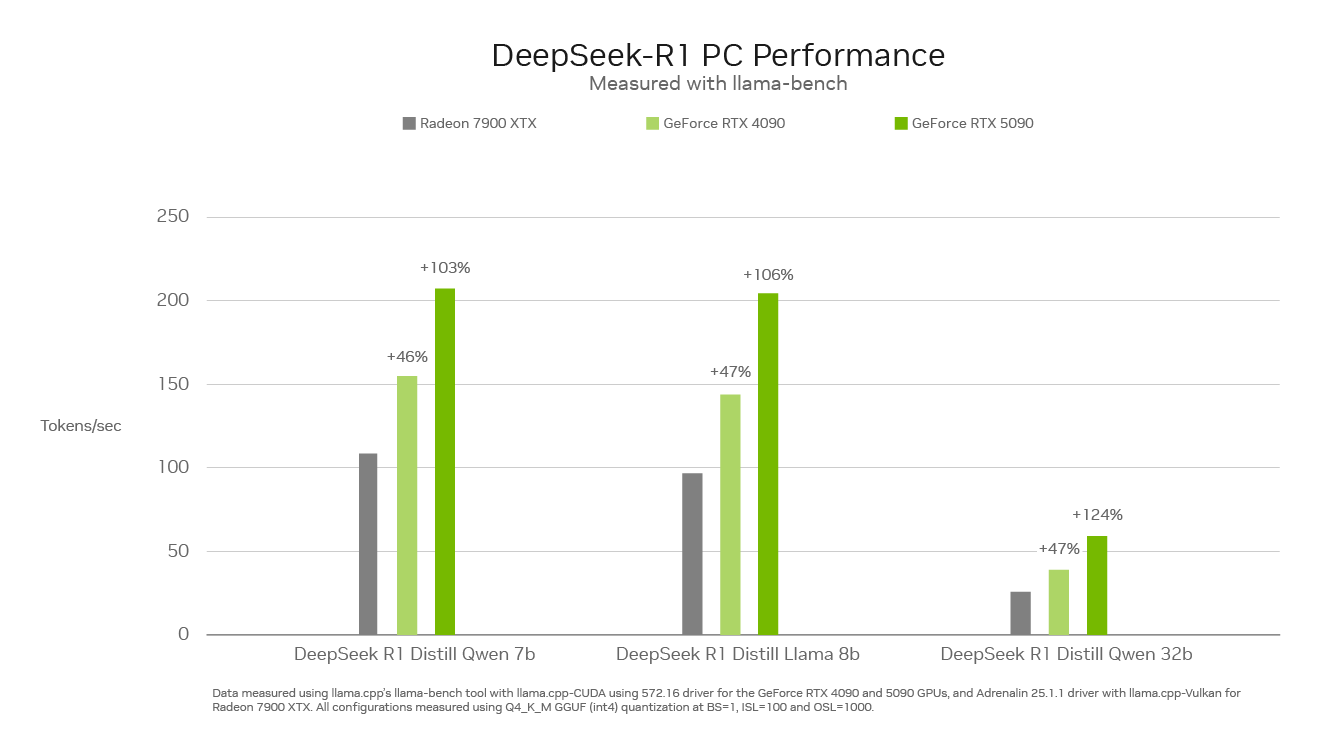
Performances de pointe sur RTX
La vitesse d’inférence est essentielle pour cette nouvelle classe de modèles de raisonnement. Les GPU de la série GeForce RTX 50, construites avec des noyaux de tenseur de cinquième génération dédiés, sont basés sur la même architecture GPU Nvidia Blackwell qui alimente l’innovation de l’IA de pointe dans le centre de données. RTX accélère entièrement Deepseek, offrant des performances d’inférence maximales sur les PC.
Découvrez Deepseek sur RTX dans les outils populaires
La plate-forme RTX AI de NVIDIA propose la sélection la plus large d’outils d’IA, de kits de développement de logiciels et de modèles, ouvrant l’accès aux capacités de Deepseek-R1 sur plus de 100 millions de PC NVIDIA RTX dans le monde, y compris ceux alimentés par GeForce RTX 50 GPUS.
Les GPU RTX haute performance rendent les capacités de l’IA toujours disponibles – même sans connexion Internet – et offrent une faible latence et une confidentialité accrue car les utilisateurs n’ont pas à télécharger des matériaux sensibles ou à exposer leurs requêtes à un service en ligne.
Découvrez la puissance des PC Deepseek-R1 et RTX AI via un vaste écosystème de logiciels, y compris Llama.cpp, Olllama, LM Studio, Anythingllm, Jan.ai, GPT4All et OpenWebui, pour une inférence. De plus, utilisez un peu pour affiner les modèles avec des données personnalisées.